Plupload 介绍
Plupload 是一款由著名的 Web 编辑器 TinyMCE 团队开发的上传组件,简单易用且功能强大。Plupload 会自动侦测当前的浏览器环境,选择最合适的上传方式,并且会优先使用 HTML5 的方式。该前端插件实现原理简单来说就是将文件按照指定分块大小切割成 n 块,然后依次将这 n 块文件数据上传至服务端,可实现暂停、继续上传。这也算是断点续传的一种实现方式。
本人在使用过程中对于这个插件也遇到了一些坑,比如,上传暂停后重新开始,Plupload 会重复上传上次最后一块文件块;该问题的原因在于调用 Plupload 的 stop() 方法后 Plupload 会立刻中断本次请求,这时服务器正在处理请求,还未及时将处理结果返回至前端请求被中断了,造成服务器实际已保存该文件块,但 Plupload 认为该文件块未上传完成,导致暂停后重新开始,服务端文件块重复,服务端接收到的文件与实际不同。在本文中我将会解决这个问题。
Plupload 获取
正确的途径当然要从官网下载
本人下载版本 Plupload 2.3.6 AGPLv3,里面包含需要用到的 js,还有 Custom example 和 Events example 两个 Demo 页面。接下来将改写 Custom example 页面,实现需要的功能。
前端 HTML 页面
前端使用比较简单,通过一些简单参数配置即可使用,具体参数设置可查看官方文档,其中主要用到 Plupload 插件的 start() 和 stop() 两个方法
修改后的 Custom example 如下,附上源代码:
1 |
|
服务端,以 Spring Boot 1.5.14.RELEASE 为例
Plupload 对象
Plupload 上传文件时会附带 name, chunks, chunk 三个参数,这里我通过 Plupload 对象接收参数
1 | /** |
upload(),接收 Plupload 上传数据
本文提到上传暂停后重新开始,Plupload 会重复上传上次最后一块文件数据这一问题,这里给出一种解决办法:每次收到 Plupload 上传的文件块,处理成功后将当前文件块编号记录到缓存(缓存需要设置过期时间,防止永久驻留),暂停后重新开始,服务端比较本次上传文件块是否已在上次上传处理,如果已处理则抛弃改文件块。
如果需要支持文件秒传,可以通过验证文件 MD5 值简单实现,Java 可通过 commons-codec 包下的 DigestUtils.md5Hex(new FileInputStream(filePath))); 方法获取文件 MD5 值,该 Demo 未做文件秒传。
具体实现,请看源码:
/**
* 文件上传,断点续传,分块上传
*
* @param request
* @param response
* @param plupload
* @return
*/
public boolean upload(HttpServletRequest request, HttpServletResponse response, Plupload plupload) {
//按日期文件夹保存
Calendar calendar = Calendar.getInstance();
File serverDir = new File(System.getProperty("user.dir") + File.separator
+ "uploads" + File.separator
+ calendar.get(Calendar.YEAR) + File.separator
+ (calendar.get(Calendar.MONTH) + 1));
//mkdirs() 可创建多级目录,mkdir() 只能创建一级目录
if (!serverDir.exists()) {
if (serverDir.mkdirs()) {
//文件夹创建失败返回403
response.setStatus(HttpServletResponse.SC_FORBIDDEN);
return false;
}
}
//文件名
String fileName = plupload.getName();
//上传文件总块数
int chunks = plupload.getChunks();
//当前上传块,从 0 开始
int nowChunk = plupload.getChunk();
//文件块重复检查
ValueOperations operations = redisTemplate.opsForValue();
Object lastChunk = operations.get("UPLOAD_" + plupload.getName());
if (lastChunk != null) {
if (Objects.equals(Integer.parseInt(lastChunk.toString()), nowChunk)) {
logger.warn("文件块重复,chunks: {}, now chunk: {}, last chunk: {}", chunks, nowChunk, lastChunk);
return true;
}
}
//获取文件
MultipartHttpServletRequest multipartHttpServletRequest = (MultipartHttpServletRequest) request;
MultiValueMap<String, MultipartFile> map = multipartHttpServletRequest.getMultiFileMap();
if (map == null || map.size() <= 0) {
response.setStatus(HttpServletResponse.SC_FORBIDDEN);
return false;
}
for (String key : map.keySet()) {
List<MultipartFile> multipartFileList = map.get(key);
File targetFile = new File(serverDir + File.separator + fileName);
for (MultipartFile multipartFile : multipartFileList) {
try {
//上传文件总块数 > 1,则为分块上传,需要进行合并
if (chunks > 1) {
this.writePartFile(multipartFile.getInputStream(), targetFile, nowChunk != 0);
} else {
//上传文件总块数 = 1,直接拷贝文件内容
multipartFile.transferTo(targetFile);
}
} catch (IOException e) {
logger.error(e.getMessage());
e.printStackTrace();
response.setStatus(HttpServletResponse.SC_FORBIDDEN);
return false;
}
}
}
//记录上传块数
if (nowChunk == chunks - 1) {
redisTemplate.delete("UPLOAD_" + plupload.getName());
} else {
operations.set("UPLOAD_" + plupload.getName(), String.valueOf(nowChunk), 86400L, TimeUnit.SECONDS);
}
return true;
}
/**
* 分块写入
*
* @param inputStream
* @param file
* @param append
*/
private void writePartFile(InputStream inputStream, File file, boolean append) {
OutputStream outputStream = null;
try {
if (!append) {
//从头开始写
outputStream = new BufferedOutputStream(new FileOutputStream(file));
} else {
//追加写入
outputStream = new BufferedOutputStream(new FileOutputStream(file, true));
}
byte[] bytes = new byte[1024];
int len = 0;
while ((len = (inputStream.read(bytes))) > 0) {
outputStream.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (outputStream != null) {
outputStream.flush();
outputStream.close();
}
if (inputStream != null) {
inputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
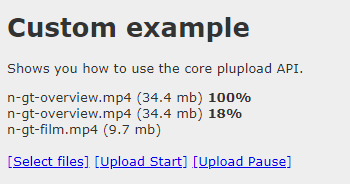
断点续传效果图